I tasked an LLM code agent (specifically, OpenDevin, now known as OpenHands) with building a vector database service using FastAPI.
The goal was to create a basic API server capable of retrieving nearest neighbors from multiple databases stored locally - essentially, a simplified version of what Pinecone offers as a service.
The Task and Initial Approach
The prompt given to the agent:
You are tasked with building a vector database service using FastAPI.
The team is interested in having an API endpoint where they can pass in
a query, namespace and identifier of the vector database, and other parameters
like number of results, and receive back the results.
The service should be flexible and allow performing lookups on many
different databases that are stored locally on disk.The agent began by using FAISS (Facebook AI Similarity Search) and creating basic read/write endpoints for the vector database. A neat experience, it seeded the database with examples to confirm its functionality.
Challenges and Iterations
Now, let's be real – things didn't exactly go smoothly from there. Our AI buddy kind of dropped the ball on the whole "storing the database on disk" thing. I had to step in and give it a nudge in the right direction.
But then things got really interesting – and expensive. Our AI agent fell into what I call the "costly doom loop." Imagine a chatty robot that charges you for every word it says, and it just can't stop talking. That was our AI, stuck in a self-correction spiral.
The kicker? We ended up paying 10 cents a pop just for the AI to restart the server "autonomously." I mean, I could've clicked that restart button myself for free, but where's the fun in that?
The Final Product
Despite the challenges, the agent eventually succeeded in creating a working server. Let's take a look at some key components of the final code:
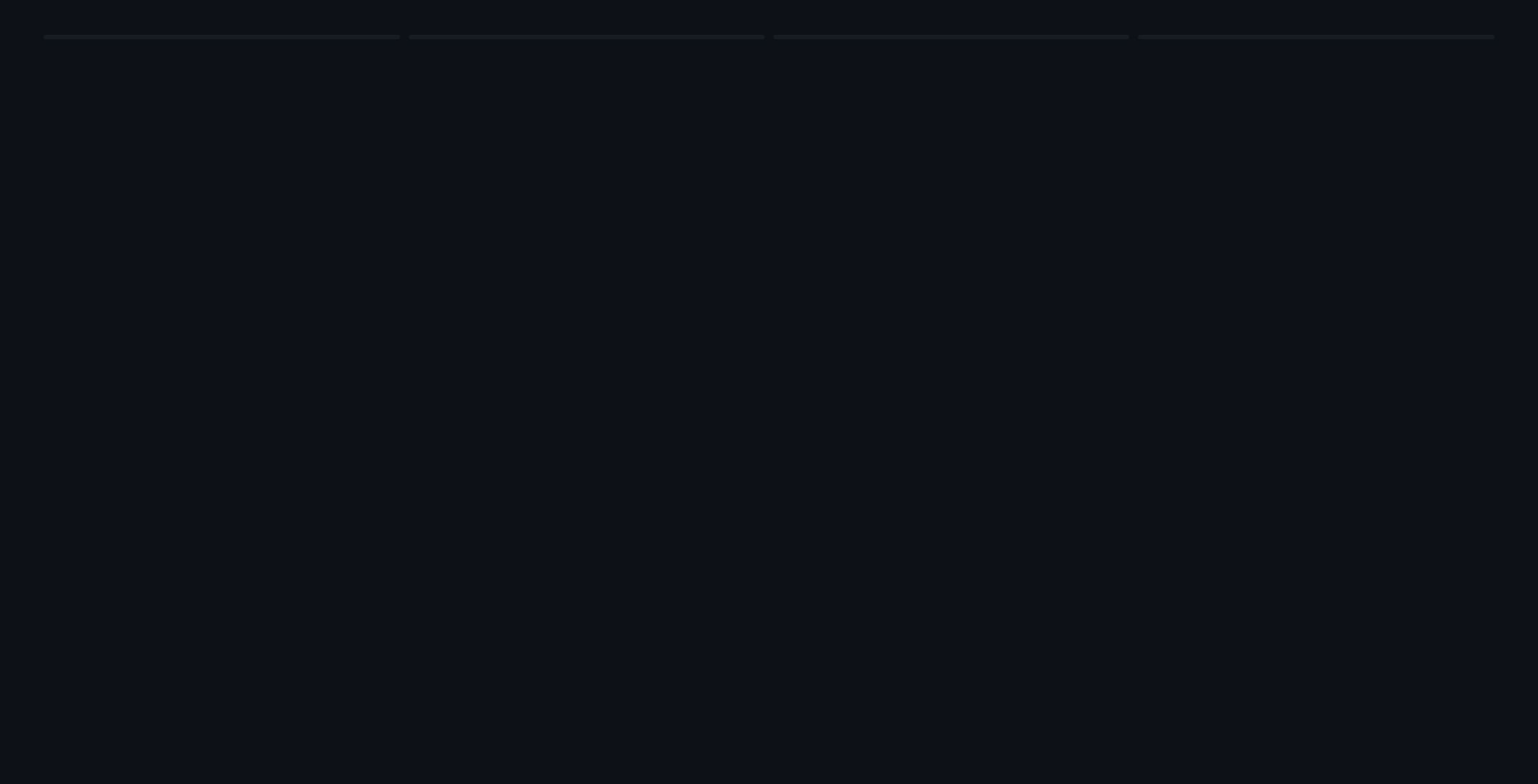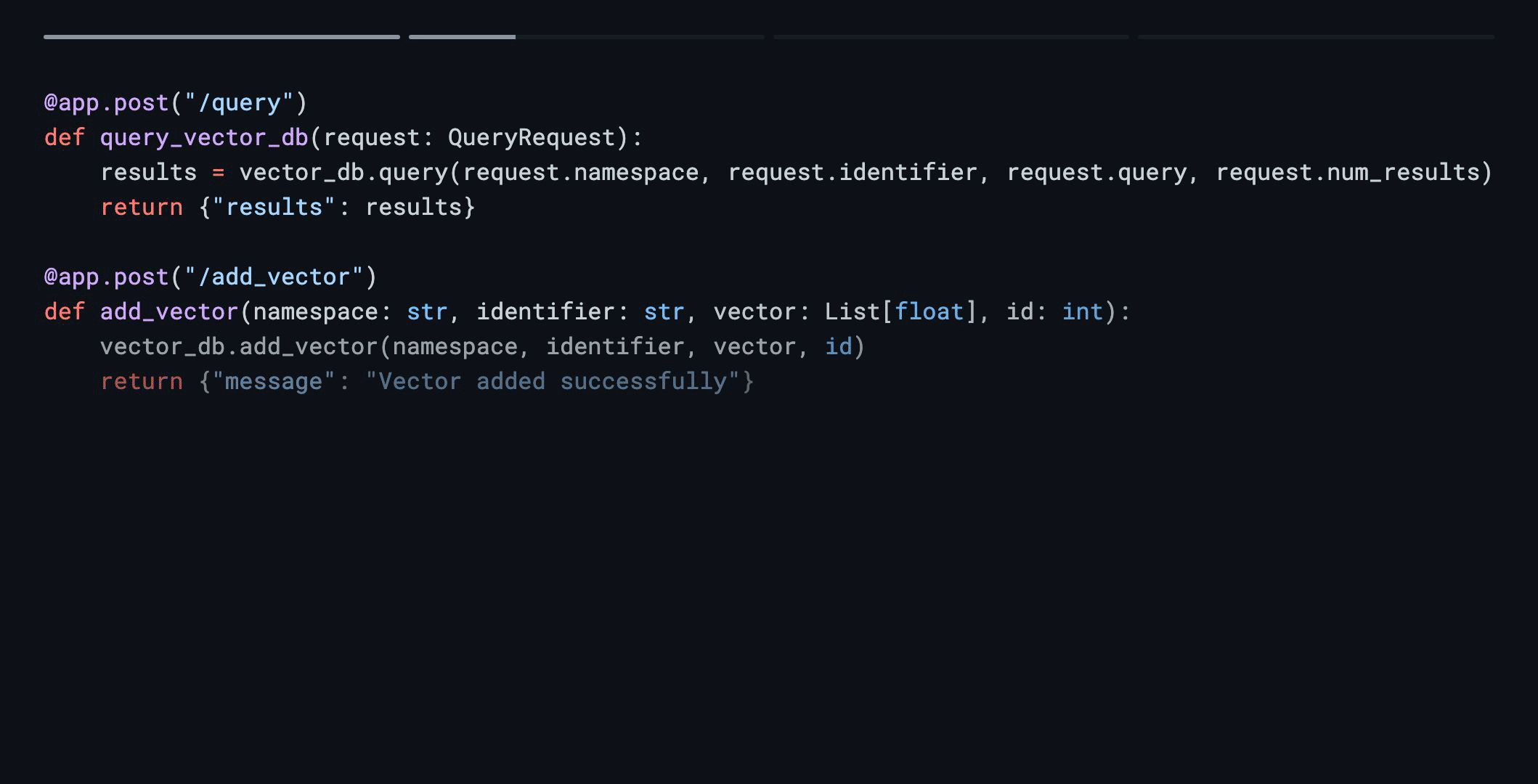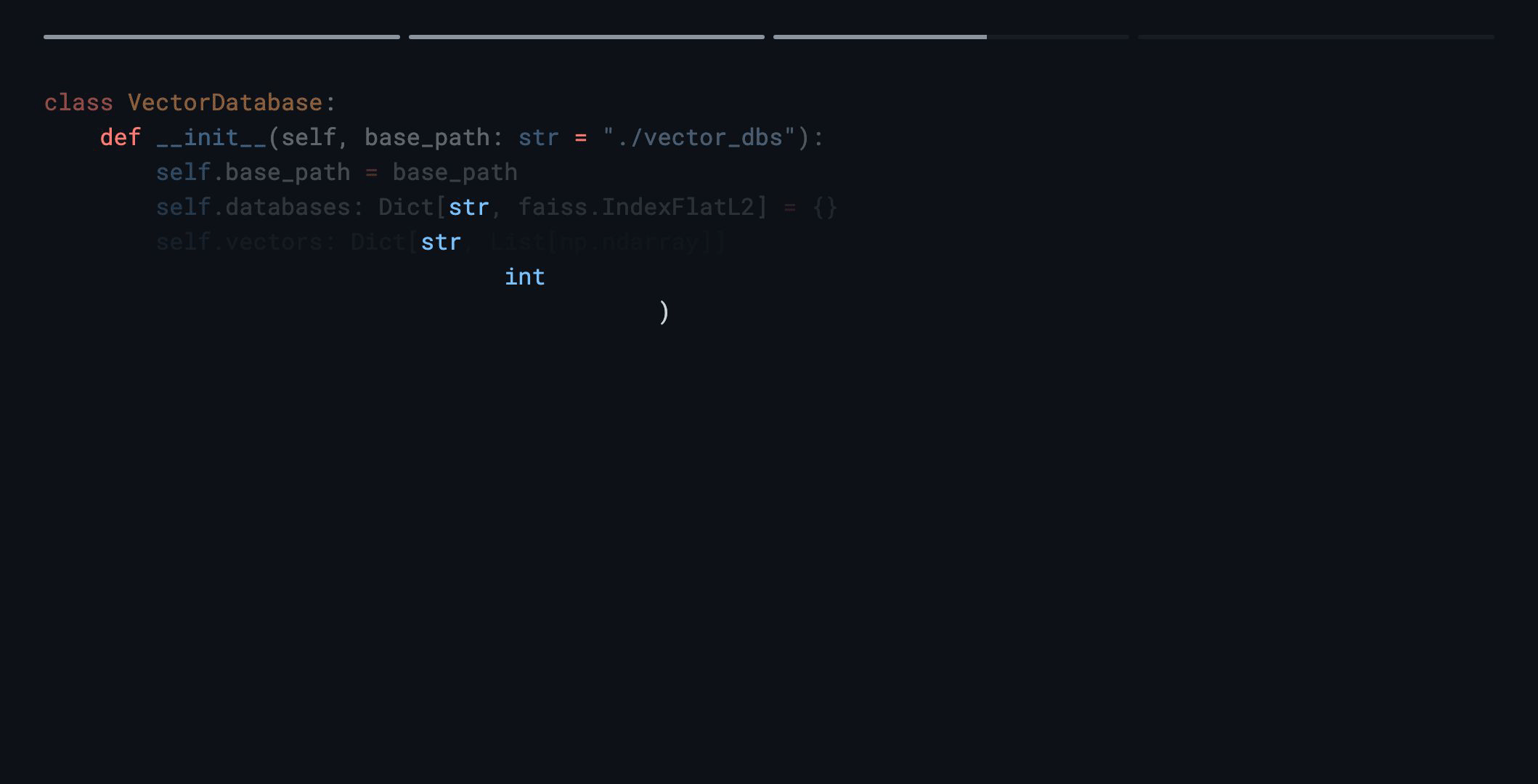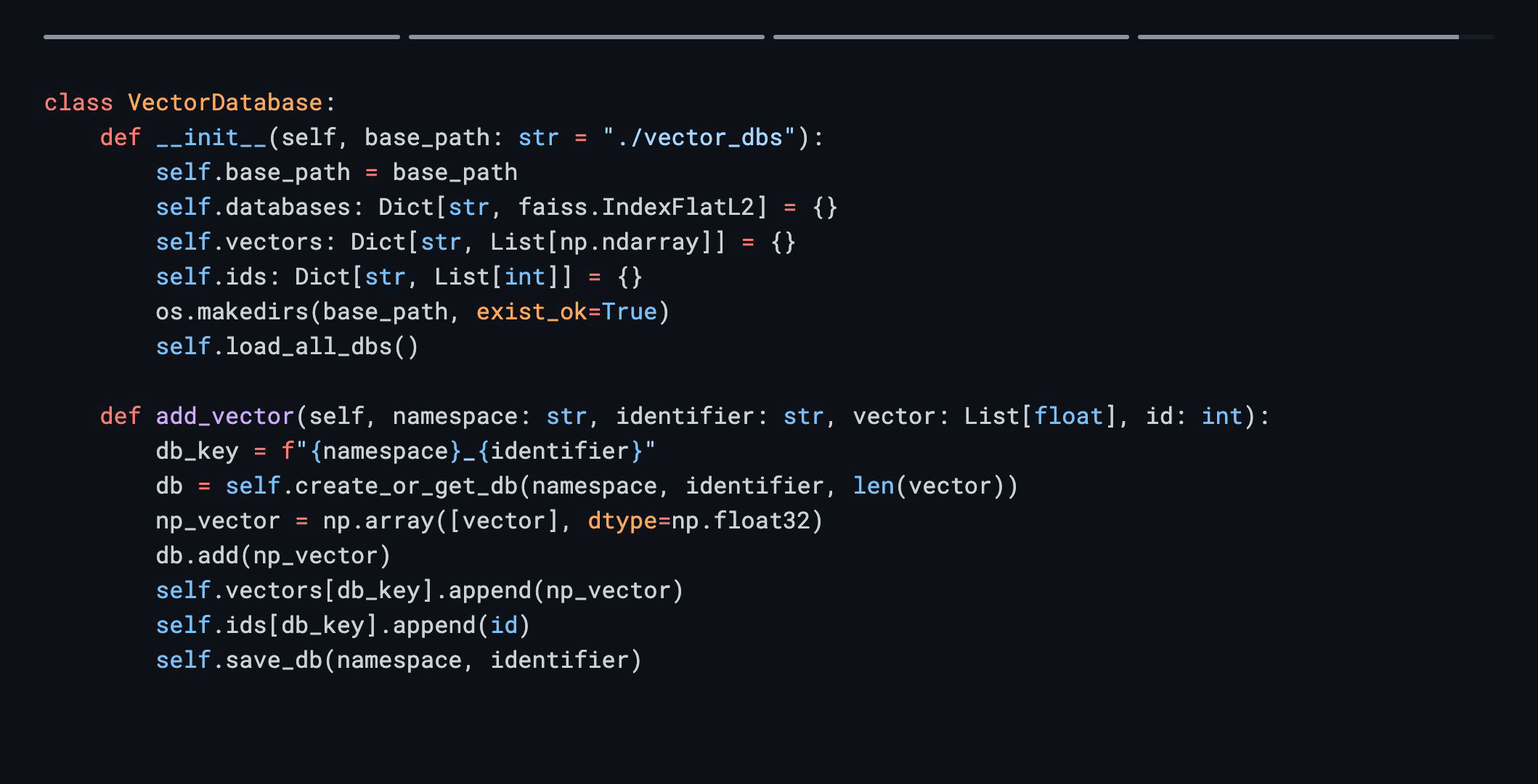
class VectorDatabase:
def __init__(self, base_path: str = "./vector_dbs"):
self.base_path = base_path
self.databases: Dict[str, faiss.IndexFlatL2] = {}
self.vectors: Dict[str, List[np.ndarray]] = {}
self.ids: Dict[str, List[int]] = {}
os.makedirs(base_path, exist_ok=True)
self.load_all_dbs()
# ... (methods for loading, saving, and querying databases)
@app.post("/query")
def query_vector_db(request: QueryRequest):
results = vector_db.query(request.namespace, request.identifier, request.query, request.num_results)
return {"results": results}
@app.post("/add_vector")
def add_vector(namespace: str, identifier: str, vector: List[float], id: int):
vector_db.add_vector(namespace, identifier, vector, id)
return {"message": "Vector added successfully"}This code demonstrates a flexible vector database service with endpoints for querying and adding vectors, fulfilling the initial requirements.
Cost Analysis
Now, let's break down the costs involved in this AI-driven development process:
- Total cost: $3.28 USD
- Cost per turn (towards the end): ~$0.10 USD
- Accumulated input tokens: 28,664
- Accumulated output tokens: 1,426
At first glance, $3.28 for a working vector database service might seem steep. However, there are a few important considerations:
- The "doom looping" significantly inflated the cost. Without these issues, the cost could have been as low as $0.10.
- Implementing prompt caching could potentially reduce costs by 90%, bringing the total down to approximately $0.40 even with the doom loop.
Is It Worth It?
To answer this question, let's compare it to traditional development costs:
If we had assigned this task to a human engineer at a rate of $50/hour, and it took them 5 minutes to complete, the cost would have been $4.16 USD.
From this perspective, even at $3.28, the AI-driven approach is more cost-effective. If we factor in potential optimizations like prompt caching, the cost savings become even more significant.
Conclusion
This experiment demonstrates the potential of AI-assisted development in creating somewhat complex tasks like vector database services. While there were challenges, particularly around error handling and cost optimization, the overall result is promising.
For businesses, exploring the technology makes sense, especially as these AI systems continue to improve and become more efficient. However, human oversight and intervention are still necessary to guide the process and ensure the final product meets all requirements.
As we continue to explore the possibilities of AI in software development, experiments like these provide valuable insights into both the capabilities and limitations of current systems. The future of coding is undoubtedly collaborative, with AI agents and human developers working together.