Introduction
The recent release of Meta's Llama 3 has generated significant interest in the AI community, particularly regarding its approach to code generation. While benchmark scores provide one metric for evaluation, I was more intrigued by the novel method Llama 3 employs to generate synthetic training data for coding tasks. This post looks into the technical details of this process, exploring its implementation and challenges.
The Challenge of AI Code Generation
Code generation presents unique challenges for AI models. Unlike natural language processing tasks, coding requires not only understanding syntax but also grasping complex logical structures, anticipating edge cases, and often incorporating domain-specific knowledge. The vast space of possible programs makes it difficult to create a comprehensive training dataset manually, necessitating innovative approaches to data generation and model training.

Llama 3's Synthetic Data Generation Approach
Meta's solution to this challenge is a self-supervised learning system that allows the AI to generate, attempt, and learn from a wide range of coding tasks. Let's break down the key components of this system:
1. Problem Generation
The process begins with Llama 3 generating diverse coding challenges. This is achieved through a clever use of existing code snippets as inspiration, allowing the model to create problems that span a wide range of programming concepts and difficulty levels.
def generate_problem(inspiration_code: str) -> str:
prompt = f"""
Given the following code snippet as inspiration:
{inspiration_code}
Generate a new, unique coding problem that explores similar concepts
or introduces a related challenge. The problem should be clear,
concise, and suitable for testing a range of programming skills.
"""
return call_llm_api(prompt)This approach ensures a constant stream of novel problems, helping to prevent overfitting and encouraging the model to develop generalizable coding skills.
2. Solution Attempt
Once a problem is generated, Llama 3 attempts to solve it. Interestingly, the model is prompted to explain its thought process through comments as it codes, mimicking the practice of writing self-documenting code.
def attempt_solution(problem: str) -> str:
prompt = f"""
Solve the following coding problem:
{problem}
As you write the solution, include comments explaining your thought process
and the reasoning behind key decisions. Ensure your code is efficient,
readable, and follows best practices for the language you're using.
"""
return call_llm_api(prompt)This step not only produces a solution but also provides valuable insight into the model's problem-solving approach, which can be used for further training and analysis.
3. Quality Assurance
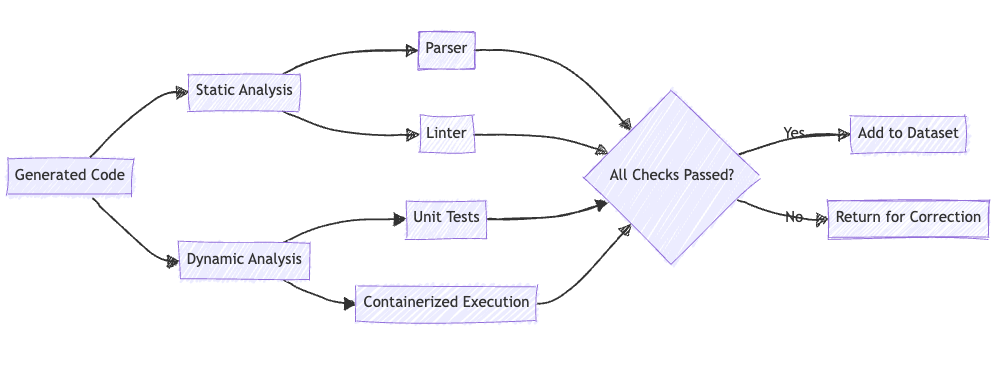
Each generated solution undergoes a series of rigorous checks to ensure its correctness and quality. This process involves both static and dynamic analysis:
def check_solution_quality(code: str) -> Tuple[bool, List[str]]:
issues = []
# Static Analysis
syntax_errors = check_syntax(code)
linter_issues = run_linter(code)
issues.extend(syntax_errors + linter_issues)
# Dynamic Analysis
unit_test_results = run_unit_tests(code)
execution_result = execute_in_container(code)
issues.extend(unit_test_results.failures + execution_result.errors)
return len(issues) == 0, issuesThis comprehensive quality assurance process ensures that only correct and well-structured code makes it into the training dataset.
4. Feedback and Iteration
If a solution fails any of the quality checks, Llama 3 receives detailed feedback and attempts to correct the code. This iterative process continues until the solution passes all checks or a maximum number of attempts is reached.
def improve_solution(code: str, issues: List[str]) -> str:
prompt = f"""
The following code has some issues:
{code}
Please address these specific problems:
{'\n'.join(issues)}
Provide an improved version of the code that resolves these issues
while maintaining the original functionality.
"""
return call_llm_api(prompt)This feedback loop is crucial for developing the model's error correction and debugging capabilities, skills that are essential for real-world programming tasks.
5. Dataset Creation
Solutions that pass all quality checks are added to the training dataset. This process resulted in the creation of approximately one million high-quality coding dialogues, with about 20% of the solutions requiring at least one round of correction before being accepted.