Building a Facial Recognition System

I recently used Large Language Models (LLMs) to create a custom video analytics platform for performing crowd analysis and recognition on protest footage. This proof of concept application took only about 3 hours to build using code generation capabilities of LLMs, demonstrating the power of LLMs to rapidly develop software solutions at low cost.
In this article, I'll share the problem I aimed to solve, my approach leveraging various AI models and tools, and the key learnings from this experience. The goal is to showcase how LLMs are changing the value proposition of our personal data, enabling us to quickly spin up personalized applications that cater to our specific needs.
The Need for a Facial Recognition Systems in Crowd Monitoring
I wanted to build a video analytics tool that could process footage of protests or crowds and provide insights such as person identification and facial recognition. The application should allow querying the processed information based on a given face or person of interest.
My objective was to have a platform where I could upload videos, have them analyzed to detect and track individuals, and then search for specific people across the processed footage. This would enable quickly finding instances of a person in a large volume of video data.
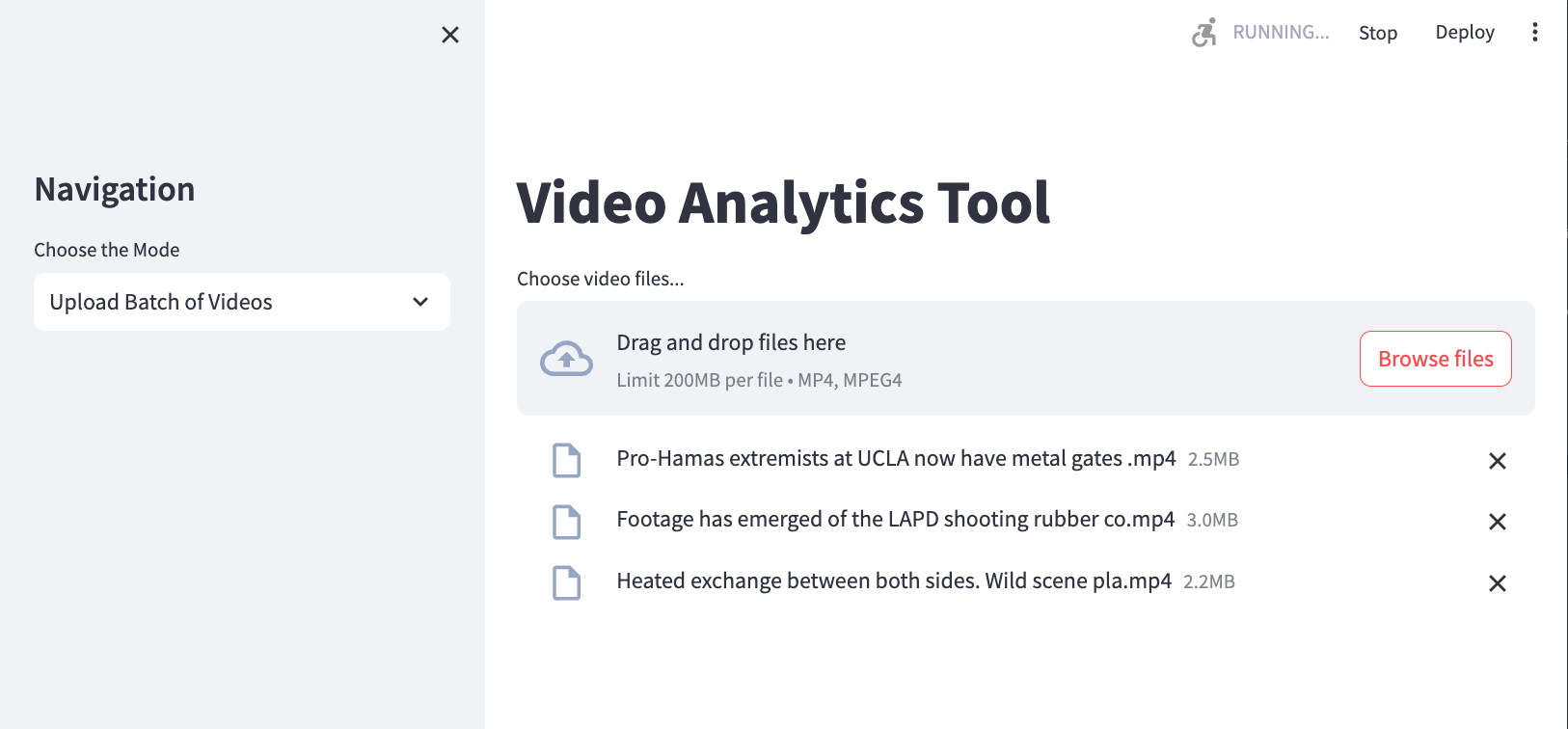
Batch upload of videos: Scaling Your Facial Recognition System
To handle large volumes of video data efficiently, I wanted to implement a batch upload feature that could process multiple videos in parallel. This would enable quick analysis of a collection of videos, making it easier to identify patterns or specific individuals across different footage.
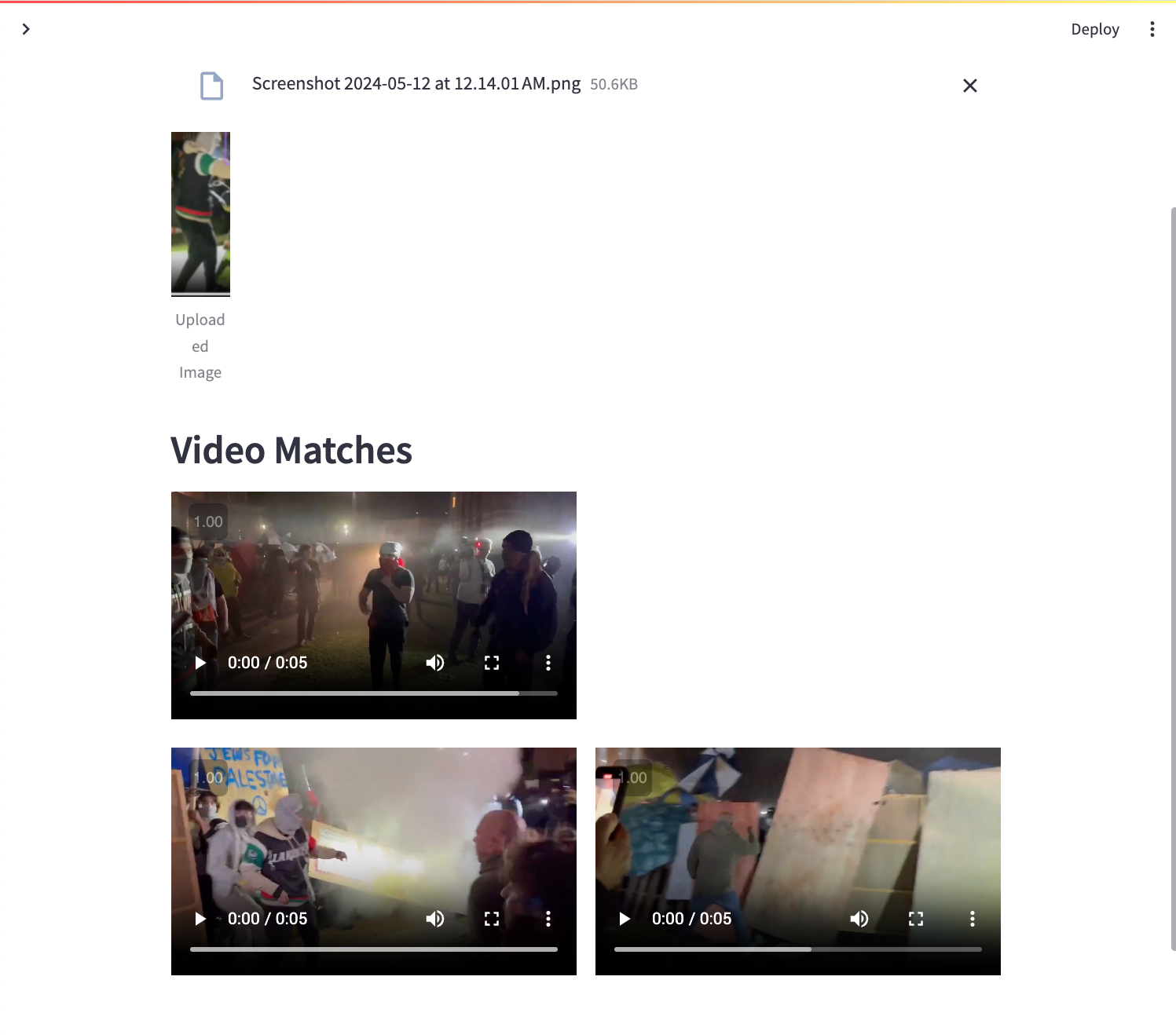
Person Matching
Here, I wanted to be able to upload an image of a person and find all instances of that person in the processed video data. This required a robust person identification and re-identification system that could handle variations in appearance, lighting, and occlusions.
Technical Approach to Building a Facial Recognition System
To tackle this challenge, I leveraged several powerful AI models and libraries:
- YOLO v8: For person detection in video frames
- Torchreid: For generating person embeddings to enable re-identification
- DeepFace: For creating facial embeddings
- Annoy: Approximate nearest neighbors library from Spotify for efficient vector similarity search
I used Python and the Streamlit framework to quickly build an interactive web application as the frontend for this tool. Streamlit allowed me to avoid the complexity of a full-fledged frontend, making it ideal for rapid prototyping.
Here's a high-level overview of the video processing pipeline I implemented:
- Upload a video file via the Streamlit UI
- Process the video frame-by-frame using YOLO v8 to detect persons
- For each detected person:
- Extract person embedding using torchreid
- Detect faces within the person bounding box using DeepFace
- Generate facial embeddings for detected faces
- Store the person and facial embeddings in a vector database (Annoy index)
- Allow querying by uploading an image of a person/face of interest
- Perform vector similarity search to find closest matches
- Display relevant video clips with the person/face found
Implementing a Facial Recognition System: Code Snippets and Details
Here are a few code snippets to illustrate key parts of the implementation:
Processing a video frame with YOLO, torchreid and DeepFace:
results = model(frame)[0]
detections = sv.Detections.from_ultralytics(results)
for i in range(detections.tracker_id.size):
bbox = detections.xyxy[i].tolist()
class_name = results.names[detections.class_id[i]]
if class_name == 'person':
person_bbox = list(map(int, bbox))
person_image = frame[person_bbox[1]:person_bbox[3], person_bbox[0]:person_bbox[2]]
person_embedding = extractor(person_image)
insert_person(conn, frame_number, video_name, json.dumps(person_embedding.tolist()), json.dumps(person_bbox))
faces = DeepFace.extract_faces(person_image, detector_backend='opencv', enforce_detection=False)
for face in faces:
embedding = DeepFace.represent(face['face'], model_name='VGG-Face', enforce_detection=False)
insert_face(conn, frame_number, video_name, embedding, face['facial_area'], face['confidence'])Querying for similar faces using the Annoy index:
def find_similar_faces(query_embedding, n_neighbors=5):
f = len(query_embedding)
u = AnnoyIndex(f, 'euclidean')
u.load('face_embeddings.ann')
indices, distances = u.get_nns_by_vector(query_embedding, n_neighbors, include_distances=True)
return indices, distancesLearnings and Insights from Building the Facial Recognition System
This experience demonstrated the incredible potential of LLMs to democratize software development. Some key takeaways:
- Code generation capabilities of LLMs can significantly accelerate prototyping and building custom applications
- Leveraging pre-trained models for specific tasks (object detection, face recognition, etc.) allows quickly assembling powerful pipelines
- Crowd data introduces unpredictable compute time due to unknown number of people in the frame
- Vector databases are highly effective for enabling semantic search over unstructured data like images/videos
- Streamlit is a great fit for rapidly building interactive 1-1 applications
While the application I built is quite niche, the overarching pattern of using LLMs to generate code snippets, stitching together existing models and tools, and packaging the solution in an easy-to-use interface is broadly applicable. This approach can enable a wider audience to create personalized software tailored to their unique needs and datasets.
Conclusion
The ability to quickly spin up a custom video analytics platform with capabilities like person identification and facial recognition using LLMs was an eye-opening experience. It showcased how this technology is putting the power of bespoke software development in the hands of individuals.
As LLMs continue to advance, I believe we'll see a proliferation of highly targeted 1 of 1 applications across diverse domains. The value of our personal data will increasingly shift towards how we can leverage it to generate useful, personalized tools to boost our productivity and gain novel insights.