
In my last tutorial, you learned about how to combine a convolutional neural network and Long short-term memory (LTSM) to create captions given an image. In this tutorial, you’ll learn how to build and train a multi-task machine learning model to predict the age and gender of a subject in an image.
Overview
- Introduction to age and gender model
- Building a Multi-task Tensorflow Estimator
- Training
Prerequisites
- basic understanding of convolutional neural networks (CNN)
- basic understanding of TensorFlow
- GPU (optional)
Introduction to Age and Gender Model
In 2015, researchers from Computer Vision Lab, D-ITET, published a paper DEX and made public their IMDB-WIKI consisting of 500K+ face images with age and gender labels.

DEX outlines an neural network architecture involving a pretrained imagenet vgg16 model that estimates the apparent age in face images. DEX placed first in ChaLearn LAP 2015 — a competition that deals with recognizing people in an image — outperforming human reference.
Age as a classification problem
A conventional way of tackling an age estimation problem with an image as input would be using a regression-based model with mean-squared error as the loss function. DEX models this problem as a classification task, using a softmax classifier with each age represented as a unique class ranging from 1 to 101 and cross-entropy as the loss function.
Multi-task learning
Multi-task learning is a technique of training on multiple tasks through a shared architecture. Layers at the beginning of the network will learn a joint generalized representation, preventing overfitting to a specific task that may contain noise.
By training with a multi-task network, the network can be trained in parallel on both tasks. This reduces the infrastructure complexity to only one training pipeline. Additionally, the computation required for training is reduced as both tasks are trained simultaneously.
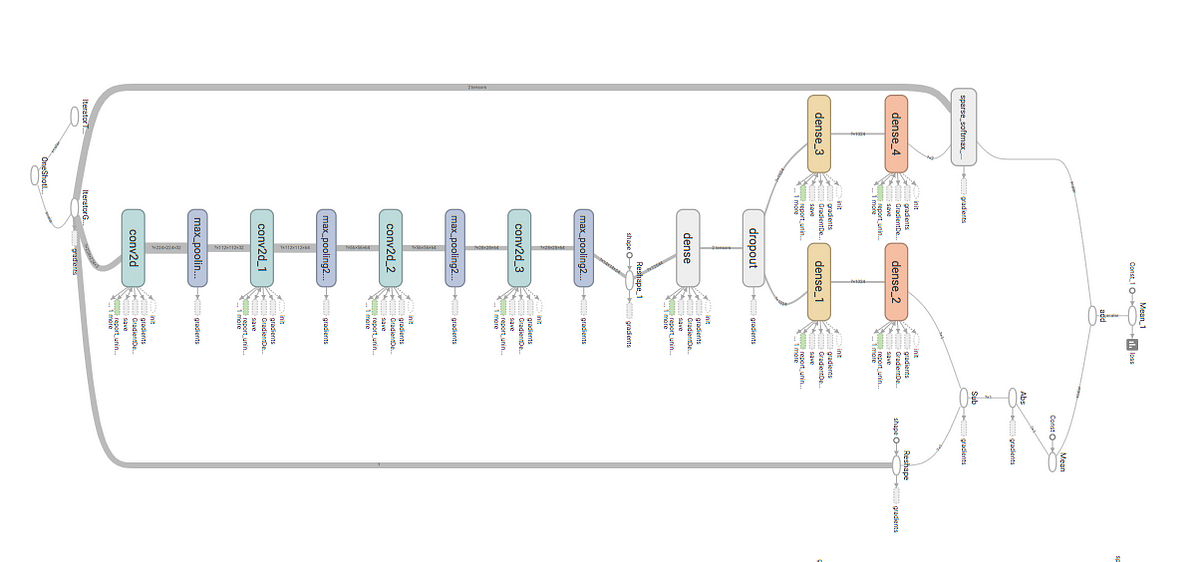
Building a multi-task network in TensorFlow
Below you’ll use TensorFlow’s estimator abstraction to create the model. The model will be trained from raw image input to predict the age and gender of the face image.
Project Structure
.
├── Dockerfile
├── age_gender_estimation_tutorial
│ ├── cnn_estimator.py
│ ├── cnn_model.py
│ └── dataset.py
├── bin
│ ├── download-imdb.sh
│ ├── predict.py
│ ├── preprocess_imdb.py
│ └── train.py
├── requirements.txtEnvironment
For the environment, you’ll use Docker to install dependencies. A GPU version is also provided for convenience.
FROM tensorflow/tensorflow:1.12.0-py3
RUN apt-get update \
&& apt-get install -y libsm6 libxrender-dev libxext6
ADD $PWD/requirements.txt /requirements.txt
RUN pip3 install -r /requirements.txt
CMD ["/bin/bash"]Dockerfile (cpu version)
FROM tensorflow/tensorflow:1.12.0-gpu-py3
RUN apt-get update \
&& apt-get install -y libsm6 libxrender-dev libxext6
ADD $PWD/requirements.txt /requirements.txt
RUN pip3 install -r /requirements.txt
CMD ["/bin/bash"]Dockerfile.gpu (GPU version)
scipy==1.1.0
numpy==1.15.4
opencv-python==3.4.4.19
tqdm==4.28.1requirements.txt
docker build -t colemurray/age-gender-estimation-tutorial -f Dockerfile .Data
To train this model, you’ll use the IMDB-WIKI dataset, consisting of 500K+ images. For simplicity, you’ll download the pre-cropped imdb images (7GB). Run the script below to download the data.
#!/usr/bin/env bash
if [[ ! -d "data" ]]
then
mkdir "data"
fi
curl https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/static/imdb_crop.tar -O
tar -xzvf imdb_crop -C datadownload-imdb-crop.sh
chmod +x bin/download-imdb-crop.sh
./bin/download-imdb-crop.shPreprocessing
You’ll now process the dataset to clean out low-quality images and crop the input to a fixed image size. Additionally, you’ll format the data as a CSV to simplify reading into TensorFlow.
import argparse as argparse
import csv
import os
import random
from datetime import datetime
import cv2
import numpy as np
from scipy.io import loadmat
from tqdm import tqdm
headers = ['filename', 'age', 'gender']
def calc_age(taken, dob):
birth = datetime.fromordinal(max(int(dob) - 366, 1))
# assume the photo was taken in the middle of the year
if birth.month < 7:
return taken - birth.year
else:
return taken - birth.year - 1
def load_db(mat_path):
db = loadmat(mat_path)['imdb'][0, 0]
num_records = len(db["face_score"][0])
return db, num_records
def get_meta(db):
full_path = db["full_path"][0]
dob = db["dob"][0] # Matlab serial date number
gender = db["gender"][0]
photo_taken = db["photo_taken"][0] # year
face_score = db["face_score"][0]
second_face_score = db["second_face_score"][0]
age = [calc_age(photo_taken[i], dob[i]) for i in range(len(dob))]
return full_path, dob, gender, photo_taken, face_score, second_face_score, age
def main(input_db, photo_dir, output_dir, min_score=1.0, img_size=165, split_ratio=0.8):
"""
Takes imdb dataset db and performs processing such as cropping and quality checks, writing output to a csv.
:param split_ratio:
:param input_db: Path to imdb db
:param photo_dir: Path to photo's directory
:param output_dir: Directory to write output to
:param min_score: minimum score to filter face quality, range [0, 1.0]
:param img_size: size to crop images to
"""
crop_dir = os.path.join(output_dir, 'crop')
if not os.path.exists(output_dir):
os.makedirs(output_dir)
if not os.path.exists(crop_dir):
os.makedirs(crop_dir)
db, num_records = load_db(input_db)
indices = list(range(num_records))
random.shuffle(indices)
train_indices = indices[:int(len(indices) * split_ratio)]
test_indices = indices[int(len(indices) * split_ratio):]
train_csv = open(os.path.join(output_dir, 'train.csv'), 'w')
train_writer = csv.writer(train_csv, delimiter=',', )
train_writer.writerow(headers)
val_csv = open(os.path.join(output_dir, 'val.csv'), 'w')
val_writer = csv.writer(val_csv, delimiter=',')
val_writer.writerow(headers)
clean_and_resize(db, photo_dir, train_indices, min_score, img_size, train_writer, crop_dir)
clean_and_resize(db, photo_dir, test_indices, min_score, img_size, val_writer, crop_dir)
def clean_and_resize(db, photo_dir, indices, min_score, img_size, writer, crop_dir):
"""
Cleans records and writes output to :param writer
:param db:
:param photo_dir:
:param indices:
:param min_score:
:param img_size:
:param crop_dir:
:param writer:
:return:
"""
full_path, dob, gender, photo_taken, face_score, second_face_score, age = get_meta(db)
for i in tqdm(indices):
filename = str(full_path[i][0])
if not os.path.exists(os.path.join(crop_dir, os.path.dirname(filename))):
os.makedirs(os.path.join(crop_dir, os.path.dirname(filename)))
img_path = os.path.join(photo_dir, filename)
if float(face_score[i]) < min_score:
continue
if (~np.isnan(second_face_score[i])) and second_face_score[i] > 0.0:
continue
if ~(0 <= age[i] <= 100):
continue
if np.isnan(gender[i]):
continue
img_gender = int(gender[i])
img_age = int(age[i])
img = cv2.imread(img_path)
crop = cv2.resize(img, (img_size, img_size))
crop_filepath = os.path.join(crop_dir, filename)
cv2.imwrite(crop_filepath, crop)
writer.writerow([filename, img_age, img_gender])
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--db-path', required=True)
parser.add_argument('--photo-dir', required=True)
parser.add_argument('--output-dir', required=True)
parser.add_argument('--min-score', required=False, type=float, default=1.0)
parser.add_argument('--img-size', type=int, required=False, default=224)
parser.add_argument('--split-ratio', type=float, required=False, default=0.8)
args = parser.parse_args()
main(input_db=args.db_path, photo_dir=args.photo_dir, output_dir=args.output_dir,
min_score=args.min_score, img_size=args.img_size) docker run -v $PWD:/opt/app \
-e PYTHONPATH=$PYTHONPATH:/opt/app \
-it colemurray/age-gender-estimation-tutorial \
python3 /opt/app/bin/preprocess_imdb.py \
--db-path /opt/app/data/imdb_crop/imdb.mat \
--photo-dir /opt/app/data/imdb_crop \
--output-dir /opt/app/var \
--min-score 1.0 \
--img-size 224After approximately 20 minutes, you’ll have a processed dataset.
Next, you’ll use TensorFlow’s data pipeline module
tf.data to provide data
to the estimator. Tf.data is an abstraction to read and manipulate a
dataset in parallel, utilizing C++ threads for performance.
Here, you’ll utilize TensorFlow’s CSV Reader to parse the data, preprocess the images, create batches, and shuffle.
import os
import tensorflow as tf
def csv_record_input_fn(img_dir, filenames, img_size=150, repeat_count=-1, shuffle=True,
batch_size=16, random=True):
"""
Creates tensorflow dataset iterator over records from :param{filenames}.
:param img_dir: Path to directory of cropped images
:param filenames: array of file paths to load rows from
:param img_size: size of image
:param repeat_count: number of times for iterator to repeat
:param shuffle: flag for shuffling dataset
:param batch_size: number of examples in batch
:param random: flag for random distortion to the image
:return: Iterator of dataset
"""
def parse_csv_row(line):
defaults = [[""], [0], [0]]
filename, age, gender = tf.decode_csv(line, defaults)
filename = os.path.join(img_dir) + '/' + filename
image_string = tf.read_file(filename)
image = tf.image.decode_image(image_string, channels=3)
image = tf.cast(image, tf.float32)
image = tf.image.per_image_standardization(image)
image.set_shape([img_size, img_size, 3])
age = tf.cast(age, tf.int64)
gender = tf.cast(gender, tf.int64)
if random:
image = tf.image.random_flip_left_right(image)
return {'image': image}, dict(gender=gender, age=age)
dataset = tf.data.TextLineDataset(filenames).skip(1)
dataset = dataset.map(parse_csv_row)
if shuffle:
dataset = dataset.shuffle(buffer_size=2000)
dataset = dataset.batch(batch_size)
dataset = dataset.repeat(repeat_count)
dataset = dataset.prefetch(batch_size * 10)
iterator = dataset.make_one_shot_iterator()
return iterator.get_next()dataset.py
Model
Below, you’ll create a basic CNN model. The model consists of three convolutions and two fully connected layers, with a softmax classifier head for each task.
import tensorflow as tf
def network(feature_input, labels, mode):
"""
Creates a simple multi-layer convolutional neural network
:param feature_input:
:param labels:
:param mode:
:return:
"""
filters = [32, 64, 128]
dropout_rates = [0.2, 0.4, 0.7]
conv_layer = feature_input
for filter_num, dropout_rate in zip(filters, dropout_rates):
conv_layer = conv_block(conv_layer, mode, filters=filter_num, dropout=dropout_rate)
# Dense Layer
pool4_flat = tf.layers.flatten(conv_layer)
dense = tf.layers.dense(inputs=pool4_flat, units=1024, activation=tf.nn.relu)
dropout = tf.layers.dropout(
inputs=dense, rate=0.4, training=mode == tf.estimator.ModeKeys.TRAIN)
# Age Head
age_dense = tf.layers.dense(inputs=dropout, units=1024)
age_logits = tf.layers.dense(inputs=age_dense, units=101)
# Gender head
gender_dense = tf.layers.dense(inputs=dropout, units=1024)
gender_logits = tf.layers.dense(inputs=gender_dense, units=2)
return age_logits, gender_logits
def conv_block(input_layer, mode, filters=64, dropout=0.0):
conv = tf.layers.conv2d(
inputs=input_layer,
filters=filters,
kernel_size=[5, 5],
padding="same",
activation=tf.nn.relu)
pool = tf.layers.max_pooling2d(inputs=conv, pool_size=[2, 2], strides=2)
dropout_layer = tf.layers.dropout(
inputs=pool, rate=dropout, training=mode == tf.estimator.ModeKeys.TRAIN)
return dropout_layercnn_model.py
Joint loss function
For the training operation, you’ll use the Adam Optimizer. For a loss function, you’ll average the cross-entropy error of each head, creating a shared loss function between the heads.
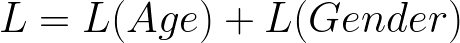
TensorFlow estimator
TensorFlow estimators provide a simple abstraction for graph creation
and runtime processing. TensorFlow has specified an interface
model_fn, that can be used to create custom estimators.
Below, you’ll take the network created above and create training, eval, and predict. These specifications will be used by TensorFlow’s estimator class to alter the behavior of the graph.
import tensorflow as tf
from age_gender_estimation_tutorial.cnn_model import network
def model_fn(features, labels, mode, params):
"""
Creates model_fn for Tensorflow estimator. This function takes features and input, and
is responsible for the creation and processing of the Tensorflow graph for training, prediction and evaluation.
Expected feature: {'image': image tensor }
:param features: dictionary of input features
:param labels: dictionary of ground truth labels
:param mode: graph mode
:param params: params to configure model
:return: Estimator spec dependent on mode
"""
learning_rate = params['learning_rate']
image_input = features['image']
age_logits, logits = network(image_input, labels, mode)
if mode == tf.estimator.ModeKeys.PREDICT:
return get_prediction_spec(age_logits, logits)
joint_loss = get_loss(age_logits, logits, labels)
if mode == tf.estimator.ModeKeys.TRAIN:
return get_training_spec(learning_rate, joint_loss)
else:
return get_eval_spec(logits, age_logits, labels, joint_loss)
def get_prediction_spec(age_logits, logits):
"""
Creates estimator spec for prediction
:param age_logits: logits of age task
:param logits: logits of gender task
:return: Estimator spec
"""
predictions = {
"classes": tf.argmax(input=logits, axis=1),
"age_class": tf.argmax(input=age_logits, name='age_class', axis=1),
"age_prob": tf.nn.softmax(age_logits, name='age_prob'),
"probabilities": tf.nn.softmax(logits, name="softmax_tensor")
}
return tf.estimator.EstimatorSpec(mode=tf.estimator.ModeKeys.PREDICT, predictions=predictions)
def get_loss(age_logits, gender_logits, labels):
"""
Creates joint loss function
:param age_logits: logits of age
:param gender_logits: logits of gender task
:param labels: ground-truth labels of age and gender
:return: joint loss of age and gender
"""
gender_loss = tf.losses.sparse_softmax_cross_entropy(labels=labels['gender'], logits=gender_logits)
age_loss = tf.losses.sparse_softmax_cross_entropy(labels=labels['age'], logits=age_logits)
joint_loss = gender_loss + age_loss
return joint_loss
def get_eval_spec(gender_logits, age_logits, labels, loss):
"""
Creates eval spec for tensorflow estimator
:param gender_logits: logits of gender task
:param age_logits: logits of age task
:param labels: ground truth labels for age and gender
:param loss: loss op
:return: Eval estimator spec
"""
eval_metric_ops = {
"gender_accuracy": tf.metrics.accuracy(
labels=labels['gender'], predictions=tf.argmax(gender_logits, axis=1)),
'age_accuracy': tf.metrics.accuracy(labels=labels['age'], predictions=tf.argmax(age_logits, axis=1)),
'age_precision': tf.metrics.sparse_precision_at_k(labels=labels['age'],
predictions=age_logits, k=10)
}
return tf.estimator.EstimatorSpec(
mode=tf.estimator.ModeKeys.EVAL, loss=loss, eval_metric_ops=eval_metric_ops)
def get_training_spec(learning_rate, joint_loss):
"""
Creates training estimator spec
:param learning rate for optimizer
:param joint_loss: loss op
:return: Training estimator spec
"""
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate)
gender_train_op = optimizer.minimize(
loss=joint_loss,
global_step=tf.train.get_global_step())
return tf.estimator.EstimatorSpec(mode=tf.estimator.ModeKeys.TRAIN, loss=joint_loss, train_op=gender_train_op)
def serving_fn():
receiver_tensor = {
'image': tf.placeholder(dtype=tf.float32, shape=[None, None, None, 3])
}
features = {
'image': tf.image.resize_images(receiver_tensor['image'], [224, 224])
}
return tf.estimator.export.ServingInputReceiver(features, receiver_tensor)cnn_estimator.py
Train
Now that you’ve preprocessed the data and created the model architecture and data pipeline, you’ll begin training the model.
import argparse
import tensorflow as tf
from medium_age_estimation_tutorial.cnn_estimator import model_fn, serving_fn
from medium_age_estimation_tutorial.dataset import csv_record_input_fn
tf.logging.set_verbosity(tf.logging.INFO)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--img-dir')
parser.add_argument('--train-csv')
parser.add_argument('--val-csv')
parser.add_argument('--model-dir')
parser.add_argument('--img-size', type=int, default=160)
parser.add_argument('--num-steps', type=int, default=200000)
args = parser.parse_args()
config = tf.estimator.RunConfig(model_dir=args.model_dir,
save_checkpoints_steps=1500,
)
estimator = tf.estimator.Estimator(
model_fn=model_fn, config=config, params={
'learning_rate': 0.0001
})
train_spec = tf.estimator.TrainSpec(
input_fn=lambda: csv_record_input_fn(args.img_dir, args.train_csv, args.img_size, shuffle=False),
max_steps=args.num_steps,
)
eval_spec = tf.estimator.EvalSpec(
input_fn=lambda: csv_record_input_fn(args.img_dir, args.val_csv, args.img_size, batch_size=1, shuffle=False,
random=False),
)
tf.estimator.train_and_evaluate(estimator, train_spec, eval_spec)
estimator.export_savedmodel(export_dir_base='{}/serving'.format(args.model_dir),
serving_input_receiver_fn=serving_fn,
as_text=True)train.py
docker run -v $PWD:/opt/app \
-e PYTHONPATH=$PYTHONPATH:/opt/app \
-it colemurray/age-gender-estimation-tutorial:gpu \
python3 /opt/app/bin/train.py \
--img-dir /opt/app/var/crop \
--train-csv /opt/app/var/train.csv \
--val-csv /opt/app/var/val.csv \
--model-dir /opt/app/var/cnn-model \
--img-size 224 \
--num-steps 200000Predict
Below, you’ll load your age and gender TensorFlow model. The model will be loaded from disk and predict on the provided image.
import logging
from argparse import ArgumentParser
import tensorflow as tf
from scipy.misc import imread
from tensorflow.contrib import predictor
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
tf.logging.set_verbosity(tf.logging.INFO)
if __name__ == '__main__':
parser = ArgumentParser(add_help=True)
parser.add_argument('--model-dir', required=True)
parser.add_argument('--image-path', required=True)
args = parser.parse_args()
prediction_fn = predictor.from_saved_model(export_dir=args.model_dir, signature_def_key='serving_default')
batch = []
image = imread(args.image_path)
output = prediction_fn({
'image': [image]
})
print(output)predict.py
# Update the model path below with your model
docker run -v $PWD:/opt/app \
-e PYTHONPATH=$PYTHONPATH:/opt/app \
-it colemurray/age-gender-estimation-tutorial \
python3 /opt/app/bin/predict.py \
--image-path /opt/app/var/crop/25/nm0000325_rm2755562752_1956-1-7_2002.jpg \
--model-dir /opt/app/var/cnn-model-3/serving/<TIMESTAMP>
Conclusion
In this tutorial, you learned how to build and train a multi-task network for predicting a subject’s age and image. By using a shared architecture, both targets can be trained and predicted simultaneously.
Next Steps:
- Evaluate on Your Own Dataset
- Try a different network architecture
- Experiment with Different Hyperparameters
Questions/issues? Open an issue here on GitHub
Complete code here.
Call to Action
If you enjoyed this tutorial, follow and recommend!
Interested in learning more about Deep Learning / Machine Learning? Check out my other tutorials:
- Building an image caption generator with Deep Learning in Tensorflow - Building a Facial Recognition Pipeline with Deep Learning in Tensorflow - Deep Learning CNN’s in Tensorflow with GPUs - Deep Learning with Keras on Google Compute Engine - Recommendation Systems with Apache Spark on Google Compute EngineOther places you can find me:
Cole Murray (@_ColeMurray) | Twitter